
Will WilliamsChief Technology Officer

Today we are making several exciting announcements.
Firstly, we are making our Conversational AI system, Flow, available as an API. Enterprise demos can be made upon request to demonstrate more upcoming features and show how Flow can integrate into your enterprise workflow today.
Secondly, we are launching Flow as an iOS app for anyone to download and use free of charge. This version of the app will have selected free features and personas, whereas full functionality is coming to the API.
Not only that, but from today, Ursa 2 models are generally available to all. This is our latest generation of speech-to-text models which also now power all our speech services, including Flow.
At Speechmatics, we’re taking a very different view on how to do Conversational AI well.
Much of the noise at the moment centres around “single-model” systems, some of which are fully duplex (i.e possible to speak and listen at all times) and some of which do not use any text tokens/representations at all. In this article, I want to show why our approach is the most compelling, particularly for enterprise.
We’ve spent a lot of time evaluating all the recent approaches, both from academia and industry. Our deep experience in Speech (10+ years of R&D with many technical reinventions along the way), plus internal results and early prototypes have led us to see this space quite differently.
While single-model systems have done well in text, images, and video, audio has been stubbornly resistant to single model systems, and in particular conversational AI applications where user understanding and underlying accuracy is paramount.
This article demonstrates why our cascaded system currently outperforms single-model systems in conversational AI applications.
The speech community has long wrestled with the trade-off between single-model and cascaded systems. In short, models can either be trained directly with one large model and lots of data, or they can be broken down into parts and chained together in a cascaded system. This trade-off has come into renewed focus in recent months with the rise of next-generation Conversational AI systems.
For context, let’s start with the technical advantages of cascaded systems:
User understanding, and relatedly accuracy, are by far the most important aspects of creating a best-in-class conversational AI system. It is impossible for single-model systems to match the accuracy cascaded systems provide through training of dedicated components. Accuracy will always be sacrificed when conversational speech is distilled into a single-model. For example, word error rates (WERs) are generally 20% greater in single-model systems as compared to Speechmatics' cascaded system (see Ursa 2 for indicative results).
Much less vulnerable to unpredictable outputs, which pose significant risks for enterprises concerned with consistency and liability. For example: single-models can make an implicit ASR error on a critical word and respond severely incorrectly. It only takes one major error in a Conversational AI system’s response to ruin the user experience forever.
Individual modules can be innovated upon independently, aiding optimization and product innovation cadence. No big retraining requirement. For example: the ASR system can be updated independently of the TTS system.
Individual components can be customized at runtime without the need to retrain the full model. New data isn’t necessarily required to customize. For example: new words with their exact pronunciation can be added without any retraining.
Single-model systems need more data to train to the same performance. For example: you might train a single-model system on multiple tasks including ASR. Once you train on the final speech-to-speech objective, modern systems need to continue to train the ASR task to stop the model forgetting the basics of how to recognize words correctly. These optimization challenges result in orders of magnitude more training compute.
Single-model systems are notorious for hallucinating, recapitulating their training data and struggling in difficult acoustic conditions which are different from the training data. Crucially, when you have an ASR system, such as Speechmatics, that already operates with the highest accuracy, it is nearly impossible to re-build that capability from scratch inside a single-model. This is especially true in low latency environments, like Conversational AI.
In Conversational AI systems, increased accuracy at the lowest possible latency results in more time for the system to "think" and generate an appropriate, natural response.
Below illustrates a comparison of the latency and accuracy trade-off of several providers on the Kincaid test set (~2hrs long). Note the log scale on the x-axis, range is (0.35, 20)s.
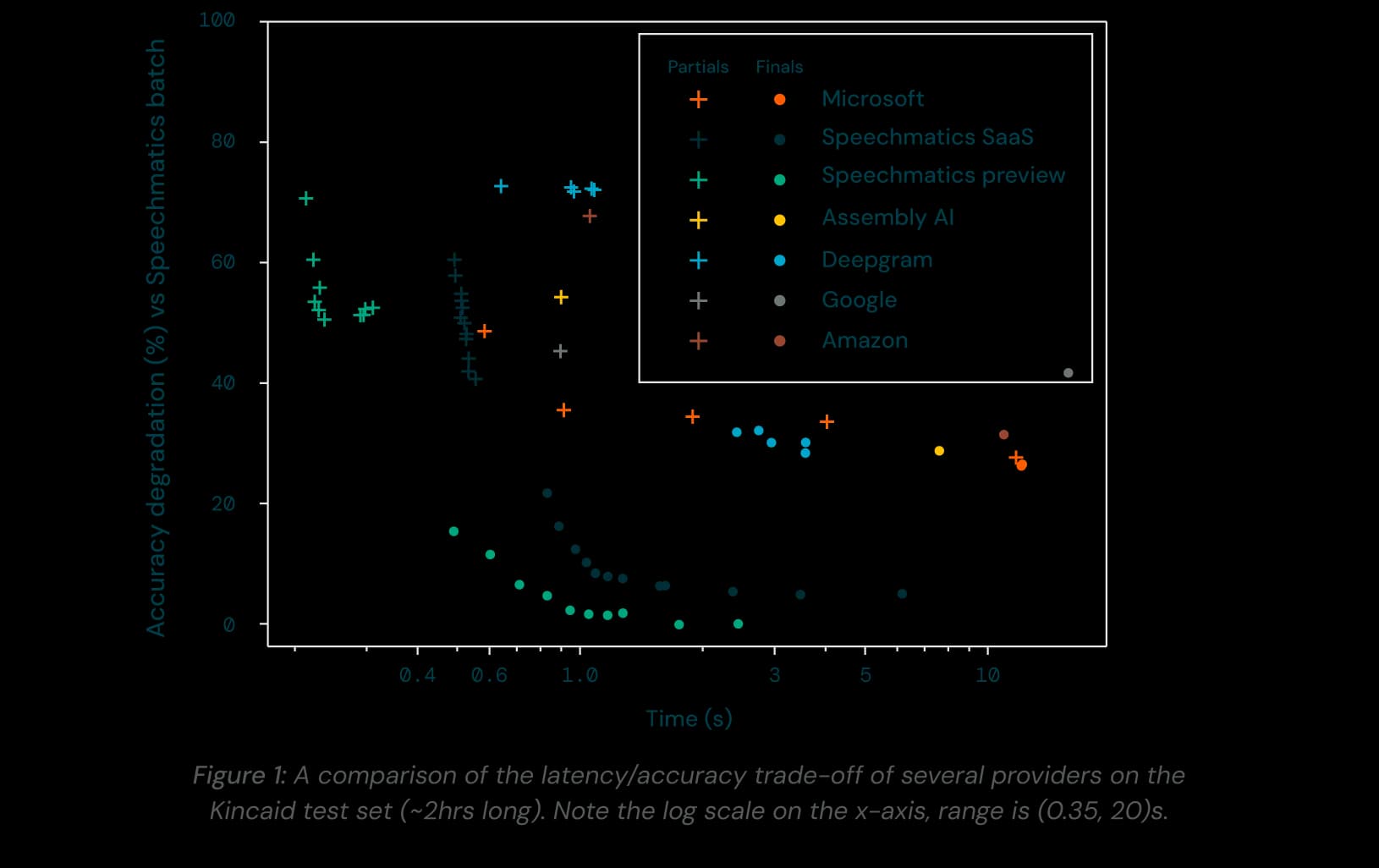
Parallel work has attempted to push latency incredibly low (<500ms) with full-duplex models that can output speech instantaneously. While an interesting long-term research proposition, these approaches go so low on latency that conversations quickly become farcical, with frequent unwanted interruptions, hallucinations, factual inaccuracies, and stilted conversational pacing.
If you want a best-in-class Conversational AI system with the greatest user understanding, flexibility, and control, and without unpredictable conversational flow and hallucinations, you must use a cascaded system as opposed to a single-model. These factors are critical for all enterprise use-cases.
Why is our differentiated approach to a cascaded model novel?
There are three aspects that are unique about our cascaded approach.
Firstly, we pass paralinguistic information such as speaking style information (the “how” it is spoken) and diarized speaker information (the “who” is speaking), through our entire cascade. Therefore, the LLM and text-to-speech (TTS) components have broad context on what is happening in the audio beyond just the words.
Secondly, we configure our LLMs and TTS systems to both generate and exploit this extra information, leading to far richer interactions.
And finally, we have optimized several internal features of our ASR and diarization systems specific to Conversational AI. This has reduced both latency and the distribution of returned finals in our real-time ASR. Single-model systems cannot make these types of improvements. (Note: The ASR and diarization optimizations will initially only be available in Flow but will be backported into our production services soon).
Beyond the technical considerations, there are several business advantages to a cascaded approach that are important to us and our customers:
Vendor agnostic - Easily switch vendors for individual components, reducing dependency and costs. Allows customers to “bring their own LLM”.
Cost-effective - More affordable to implement and scale horizontally. Cost savings can be passed on.
Customizable - Greater scope for customization, allowing interactions to maintain high ASR accuracy and brand consistency. For example the LLM persona and the TTS voice can be customized independently.
Reduced legal risk - No hallucinations and overexposure to grey data means a predictable user experience.
The strength and depth on the underlying Machine Learning together with these business-level benefits creates the strongest proposition for enterprise conversational deployments.
Speechmatics’ focus is on being the premium offering for enterprise. Our experience in ASR tells us that control, predictability and customizability is critical at the foundational “speech-in” layer.
We know that enterprise use cases will need stronger guarantees and high-trust; as such our approach delivers reliable custom dictionary, best-in-class diarization, the most inclusive and broad ASR and pareto-optimal low-latency real-time ASR accuracy.
In terms of the overall Conversational AI experience, this means that the hardest most technical discussions stay on track and difficult accents or environments don’t confuse the system.
We natively support multi-speaker interactions - a key differentiator. We understand who you are with market leading reliability in real-time.
No one else is doing this.
It also opens the possibility for long term interactions with the AI system without a mistaken case of identity and graceful handling of multi-speaker in-person meetings. Our strength in any language will translate to immediately compelling personas in those languages.
Many things need to come together to have engaging and repeatable useful conversations that go beyond gimmicks. Since we are working within a cascaded system we can and do control several aspects of the conversation that are difficult to train into a single-model.
1) We exploit our real-time diarization to help with accurate turn taking. This means that the person in the background is correctly identified as “not you” and doesn’t interrupt the conversation.
2) We use information from our ASR engine to dynamically impact the “eagerness” of the AI system to reply to you, reducing the amount of false starts in conversational turn taking.
3) We use custom models to help predict speaker turns to keep the conversation flowing.
4) We inject paralinguistic information such as audio events and other more subtle aspects of the audio through all components in our stack to better understand intent and context.
These plus our proprietary conversational engine help our conversations stay rock solid.
What about ease of use for the developer? On that front, we are making our SaaS API available to all today which handles model orchestration and makes building a modern voice-powered application very simple.
Our commitment is to make working with our API fast, flexible and easy; we’re excited to see the experiences and products the community will build.
Standard Speechmatics enterprise-grade security and compliance will be inherited by Flow. We see taking privacy and security seriously as a differentiator.
Future releases will bring Flow on-prem for those that have increased control and data residency requirements. Thanks to the cost efficiencies of the cascaded approach, we will offer premium Conversational AI at a more affordable price point.
1) Cascaded models offer flexibility, cost effectiveness, customizability, and reliability, making them ideal for enterprise use-cases that prioritize control and consistency such as smart device assistant, form-filling assistant, multilingual retail services, contact centers, healthcare, automotive control, robotics, etc.
2) Speechmatics’ low-latency and high accuracy ASR underpins its new Conversational AI offering “Flow” which is available today both as an iOS app and an API.
3) Speechmatics best understands the “what”, “who” and “how” of Speech to deliver best-in-class Conversational AI experiences.
As we continue to push the boundaries of speech technology, and applications move beyond gimmicks, speech will become the single most inclusive, intuitive and ubiquitous way to use technology since the mouse and keyboard.
In this new era, Speechmatics will continue to offer Conversational AI systems that offer the best possible proposition for enterprise.
Our mission to understand every voice is getting bigger, and is all the more exciting for it.





![[alt: Bilingual medical model featuring terms related to various health conditions and medications in Arabic and English. Key terms include "Chronic kidney disease," "Heart attack," "Diabetes," and "Insulin," among others, displayed in an organized layout.]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2F3I31FQHBheddd0CibURFBv%2F4355036ed3d14b4e1accb3fe39ecd886%2FArabic-English-blog-Jade-wide-carousel.webp&w=3840&q=75)
![[alt: Illuminated ancient mud-brick structures stand against a dusk sky, showcasing architectural details and textures. Palm trees are in the foreground, adding to the setting's ambiance. Visually captures a historic site in twilight.]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2F2qdoWdIOsIygVY0cwl8UD4%2Fe7725d963a96f84c87d614ccc6cce3c6%2FAdobeStock_669627191-wide-carousel.webp&w=3840&q=75)

![[alt: Healthcare professionals in scrubs and lab coats walk briskly down a hospital corridor. A nurse uses a tablet while others carry patient charts and attend to a gurney. The setting conveys a busy, clinical environment focused on patient care.]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2F3TUGqo1FcOmT91WhT3fgbo%2F9a07c229c11f8cbe62e6e40a1f8682c7%2FImage_fx__8__1-wide-carousel.webp&w=3840&q=75)