
Liam SteadmanAccuracy Team Lead

Will WilliamsChief Technology Officer

Speechmatics has released Ursa 2, our latest generation of speech recognition models, and with a major advancement in accuracy across all of our supported languages.
It represents a significant step forward from our previous generation, which themselves were industry leading across a diverse range of languages, dialects and accents:
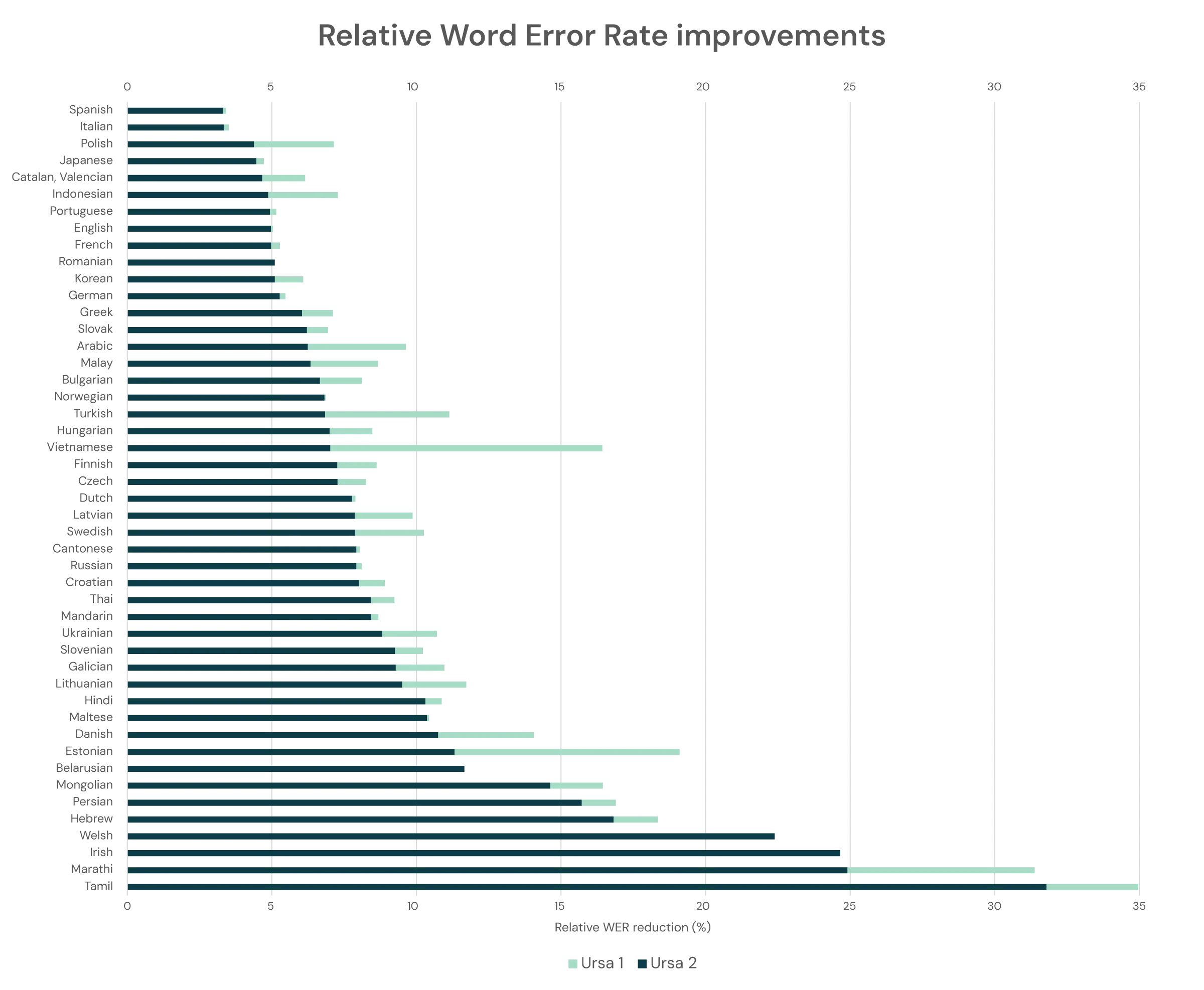
Ursa 2 achieved an 18% reduction in word error rate (WER) across 50 languages compared to our previous Ursa model.
Our global Arabic language pack has undergone significant improvements, outperforming competitors across all dialects, including Egypt, Gulf, Levant and Modern Standard Arabic.
We’ve added Irish and Maltese to our offerings, ensuring coverage of all 24 major European languages.
We've reduced latency in our real-time transcription to <1 second, all while maintaining industry-leading accuracy.
We have spoken before about the importance of accuracy, but it is worth restating.
Speech recognition and technology is often ‘foundational’ – applications, products and features are often built ‘on top’ of text generated from audio.
This means that errors in transcription can be spread within any system built on top of it, and the errors can compound. This is vital across industries, from media captioning and intelligence through to the newest generation of conversational AI agents and assistants.
Solid foundations, and highly accurate ASR are therefore vital to building valuable technology with speech as part of its stack. This is especially important for technology designed for industries that rely of technical terms and jargon, and where close enough is not good enough.
This solidity cannot be restricted to English spoken in a narrow range of accents – for us, consistency in our accuracy is key. We aim to provide speech technology that can be trusted, no matter the language, dialect, accent or noise environment.
The latest Ursa 2 models have continued our development of self-supervised learning (SSL) models.
This approach continues to give us huge benefits when faced with a bottleneck in the amount of labelled data available to us. In simple terms, there simply isn’t enough human-transcribed audio to cover every language, accent and dialect to guarantee high accuracy using supervised learning approaches to ASR.
Our SSL approach allows us to pre-train our models, by first immersing them in huge quantities of unlabelled data. Then, we couple this with more targeted training for a specific language, allowing us to reach high levels of accuracy, even if there is not thousands of hours of labelled data for that language.
A good analogy is that of a child learning a language.
When we are little, we do not receive formal language lessons (which here is the equivalent of received labelled data). Instead we simply are surrounded by people speaking and communicating with us and each other. Eventually, we spot patterns, imitate sounds ourselves and learn our first language like this.
Now imagine a child genius (think of Matilda as penned by Roald Dahl). Now, drop off Matilda at a large language school in a metropolitan area with hundreds of classrooms filled with students talking the world’s languages and return a few months later.
You can imagine that Matilda, despite not being enrolled in any formal classes, will have wandered the halls and by dropping into dozens of classes, over time will have not only picked up most of the languages spoken, but also have been able to spot patterns and commonalities between the languages, even if she hadn’t been taught this. You can well imagine that after this, Matilda would be able to learn new languages (even ones not taught at our fictional language school) incredibly quickly.
This is what we have done here at Speechmatics. This ‘pre-training’ gives us a huge head start with learning new languages, but also ensures we can achieve high accuracy across different languages and dialects.
For Ursa 2, we upped the amount of pre-training we have done, and increased the size of our ‘body model’.

We have combined this with other enhancements, including a complete shift over to GPU inference, and further reduction in our live transcription latency.
Assessing the accuracy of any speech-to-text provider can be more difficult than it first appears.
Though the FLEURS dataset is excellent in that it is publicly available and therefore transparent, it comes with its own challenges. Since it is publicly available, ASR providers can use it in the training of their models, and therefore accuracy scores can be artificially inflated compared to what you would see when using real data.
However, since it is often used as the benchmark, we will use it here to show improvements between Ursa and Ursa 2.
We have also used Word Error Rater (WER) as a measure. Accuracy can be calculated as 100 – WER.
Five key highlights include:
Ursa 2 achieved an 18% reduction in WER across 50 languages compared to our previous Ursa model.
Our global Arabic language pack has undergone significant improvements, outperforming competitors across all dialects, including Egypt, Gulf, Levant and Modern Standard Arabic.
We’ve added Irish and Maltese to our offerings, ensuring coverage of all 24 major European languages.
We've reduced latency in our real-time transcription to <1 second, all while maintaining industry-leading accuracy.

Our enhanced model has already been benchmarked as the leader in our market.
Ursa 2 improves on these benchmarks across all of our 50+ supported languages.
Some highlights:
Our Spanish WER is just 3.3 (that’s 96.7% accuracy), the best on the market.
Our Polish WER is just 4.4 (that’s 95.4% accuracy), the best on the market.
In cases where we have the lowest WER, often our lead is significant...

The numbers below shows Ursa 2’s results on the FLEURS dataset alongside others in the industry.
Focusing first on the results, rather than specific competitors, we see that in 62% of the languages, Speechmatics it is the most accurate on the market. In 92% of the languages, Speechmatics is in the top three. Finally, in a head-to-head comparison of all languages by all providers, Speechmatics wins 88% of the time.
This reliability gives you the confidence to expand your services without compromising on quality.
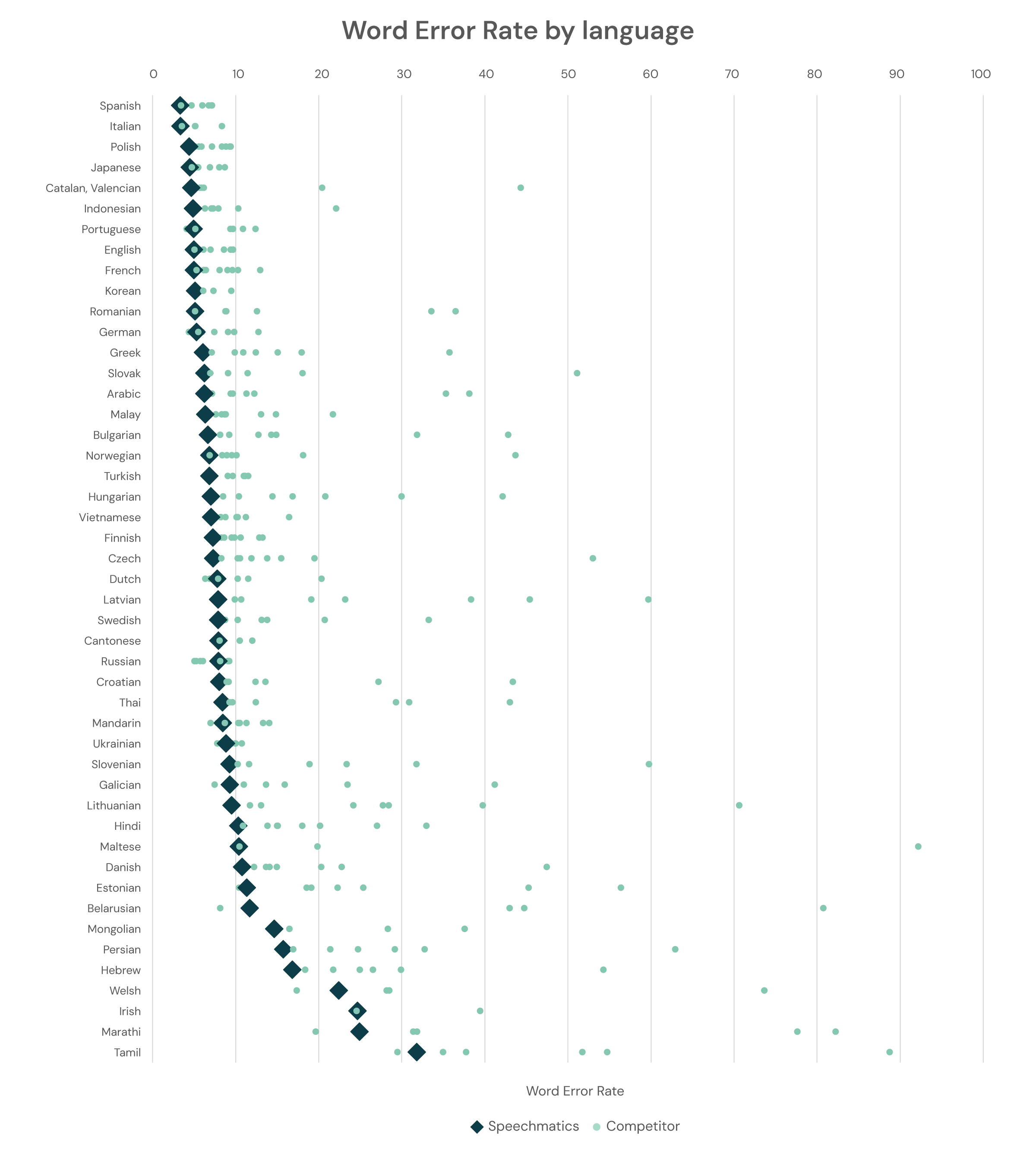
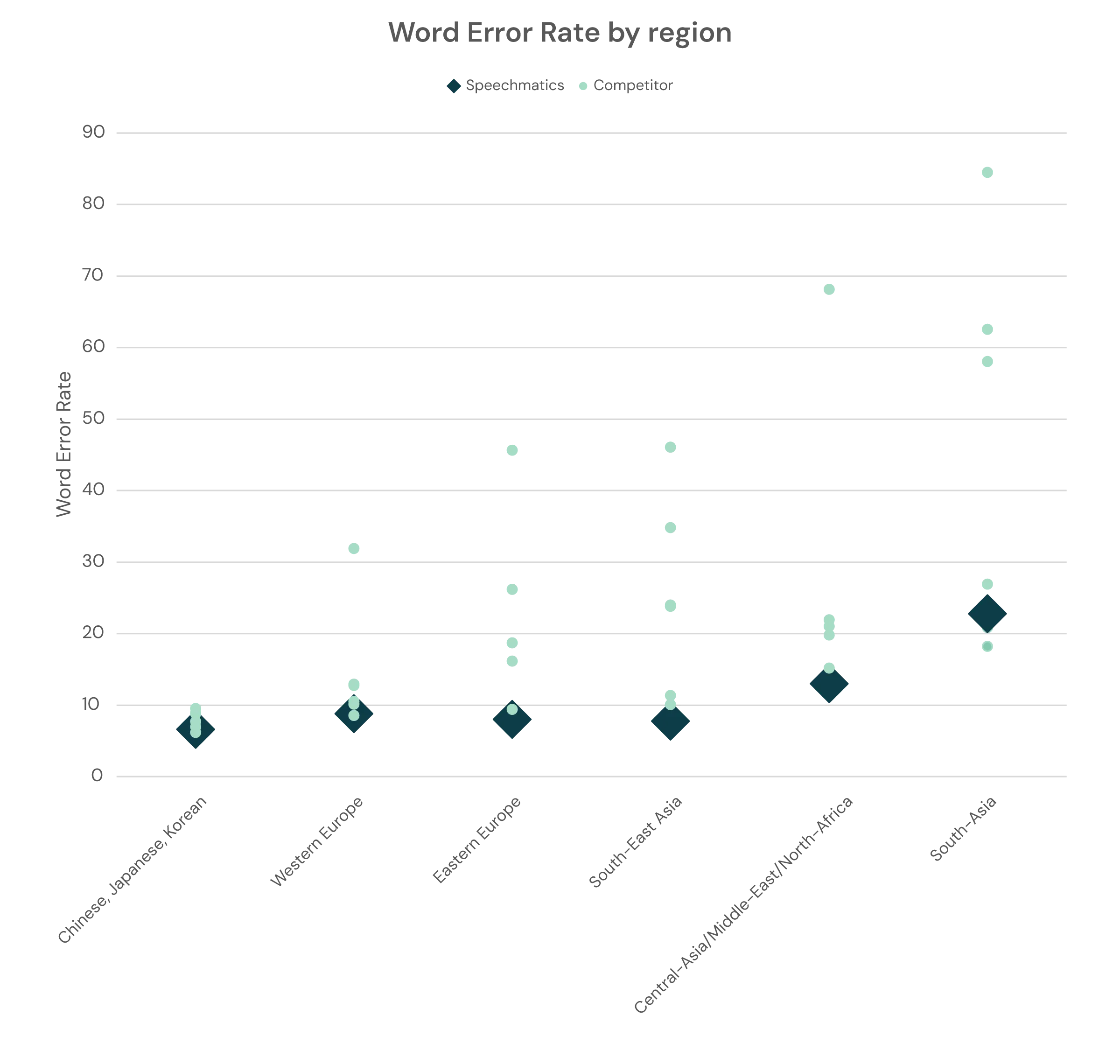
When looking at specific competitors, we see that across all supported languages, on average Speechmatics outperforms the competition.
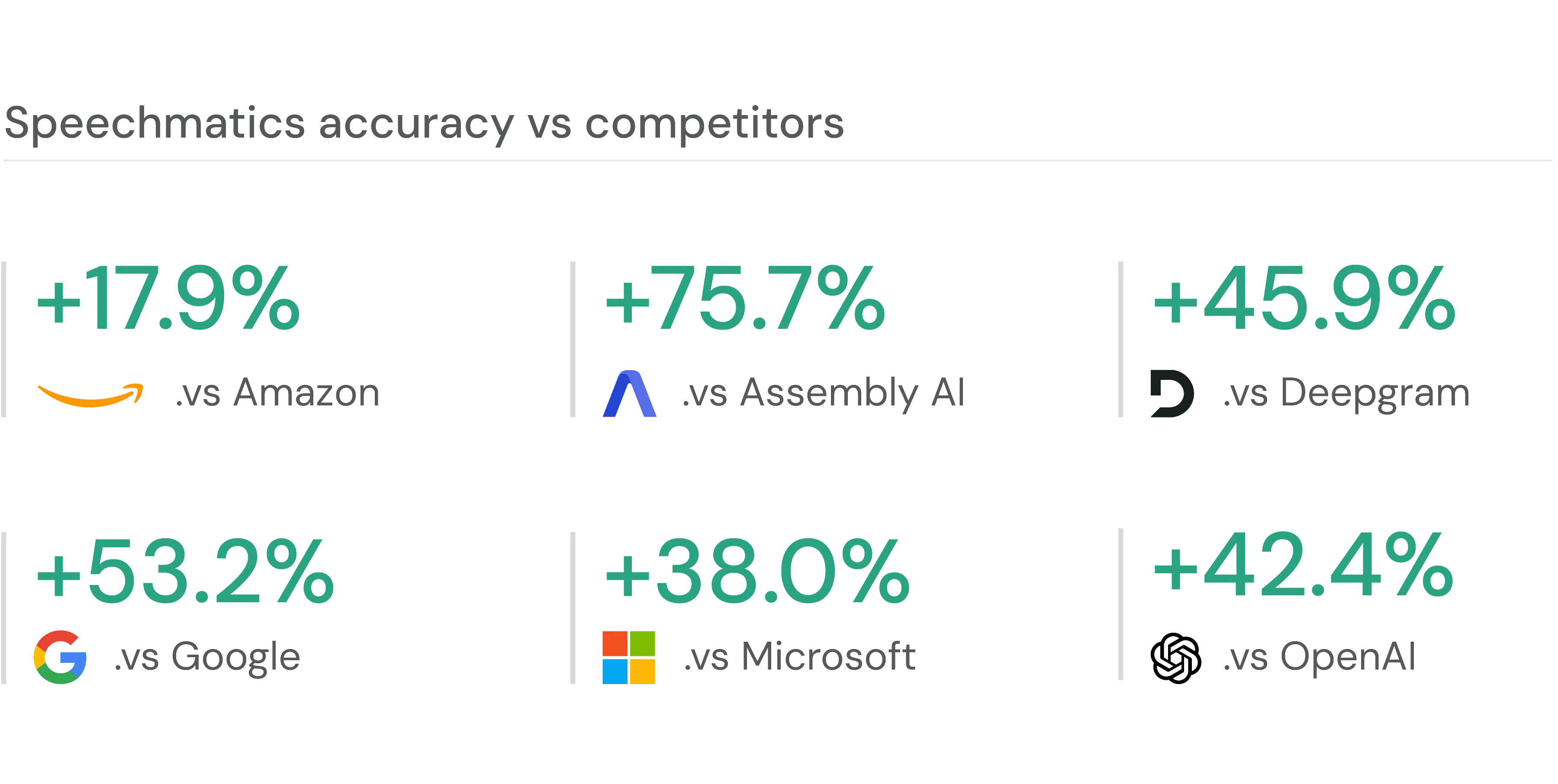
We take enormous pride in our ASR accuracy across the 50+ languages we support.
The current state of the ASR landscape means that almost every provider claims to be the ‘most accurate’ or claim the ‘lowest Word Error Rate’.
This is a badge that easy to claim and difficult to disprove given the nuances and opaqueness of testing and evaluating speech-to-text, though of course it is also a title we’d love to claim.
The above analysis supports our notion that we offer marketing-leading transcription across our offering when taken as a whole.
But what if you’re still skeptical?
Perhaps more usefully though is to think of Ursa 2 (and therefore Speechmatics) as offering consistently high accuracy. Our SSL approach coupled with our expertise built over a decade means that you can rely on Speechmatics to achieve the accuracy you need to build with.
Why is this important?
We understand that our customers and partners use us because they are experts in their industry, and not in speech technology.
The more time spent troubleshooting their speech-to-text, and correcting transcription errors, the less time they can focus on delivering enormous value to their own customers.
With consistently high accuracy, our customers trust our transcription.
No matter what they throw at it, they know they’ll get the most accurate written version possible.
An analogy might be that of an Olympic heptathlete. Though the overall winner might come second in a single event by a few points, their performance across the entire event still brings them out on top. It is also unlikely that the overall winner will be truly ‘bad’ at any one event.
Consistent high performance wins medals.
With Ursa 2, we think we’ve earnt gold.
Head to over to our portal now where Ursa 2 is available to try.
Ursa 2 also powers Flow, our latest innovation in Conversational AI. Flow enables companies to add natural, seamless speech interactions with any product. For those building AI assistants and voice agents, Ursa 2 ensures that every interaction is powered by the best ASR available today.


![[alt: Bilingual medical model featuring terms related to various health conditions and medications in Arabic and English. Key terms include "Chronic kidney disease," "Heart attack," "Diabetes," and "Insulin," among others, displayed in an organized layout.]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2F3I31FQHBheddd0CibURFBv%2F4355036ed3d14b4e1accb3fe39ecd886%2FArabic-English-blog-Jade-wide-carousel.webp&w=3840&q=75)
![[alt: Illuminated ancient mud-brick structures stand against a dusk sky, showcasing architectural details and textures. Palm trees are in the foreground, adding to the setting's ambiance. Visually captures a historic site in twilight.]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2F2qdoWdIOsIygVY0cwl8UD4%2Fe7725d963a96f84c87d614ccc6cce3c6%2FAdobeStock_669627191-wide-carousel.webp&w=3840&q=75)

![[alt: Healthcare professionals in scrubs and lab coats walk briskly down a hospital corridor. A nurse uses a tablet while others carry patient charts and attend to a gurney. The setting conveys a busy, clinical environment focused on patient care.]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2F3TUGqo1FcOmT91WhT3fgbo%2F9a07c229c11f8cbe62e6e40a1f8682c7%2FImage_fx__8__1-wide-carousel.webp&w=3840&q=75)
