John HughesAccuracy Team Lead

Word Error Rate (WER) has been the primary accuracy metric used to evaluate Automatic Speech Recognition (ASR) systems for decades.
WER is a valuable tool and a common metric for measuring and comparing the performance of a AI speech technologies. Engineers use it to make research decisions and customers use it to evaluate vendors, especially when assessing ASR technology and speech recognition systems.
The WER metric is widely used to compare different speech recognition systems and track improvements over time. Many multi-million-pound deals can often hinge directly on small differences between vendors. But WER has many flaws. The most notable is the level of importance given to certain mistakes.
Is it important to penalize an extra um, a missing hyphen, or an alternative spelling? Or how about a difference in written numerical formatting (1,000 vs 1000 or eleven vs 11)? These examples increase WER but do not affect meaning in the slightest.
Then again, how about omitting the word ‘suspected’ before murderer? Or predicting a wrong word that changes the sentiment? An ideal metric would know these examples are serious errors and score a system appropriately.
While WER is a useful metric, it should not be the only metric used to evaluate ASR accuracy; other evaluation metrics and qualitative assessments are also important. A lower WER generally indicates higher ASR accuracy, but this does not always reflect the true usefulness of the transcript.
WER is often used to compare the performance of one system to another, but differences in datasets and evaluation metrics can affect the results. Word accuracy is another metric sometimes used alongside WER to provide a more balanced view of system performance.
We have another blog on this topic - looking at the novel work Speechmatics is doing to find a more meaningful metric aligned with human perception of quality by harnessing the power of large language models.
To calculate WER, the process of calculating word error rate involves aligning the reference transcript (ground truth) and the recognized transcript.
This is done by minimizing the Levenshstein distance (or edit distance) between the two texts. Levenshtein distance is a string metric used to compute the minimum number of edits needed to transform one sequence into another, which forms the basis of the WER calculation.
After this, you can count the number of substitutions (S), insertions (I), and deletion (D) errors. The reference transcript serves as the ground truth for evaluating ASR model performance.
The WER is simply the proportion of the total number of errors over the number of words in the reference, where the total number of errors (substitutions, insertions, deletions) is divided by the total words or words spoken in the reference transcript.
This is often described as errors divided by total words spoken. If all the words are correct, then the WER is zero and that’s what developers are aiming to drive towards with every research decision they take.
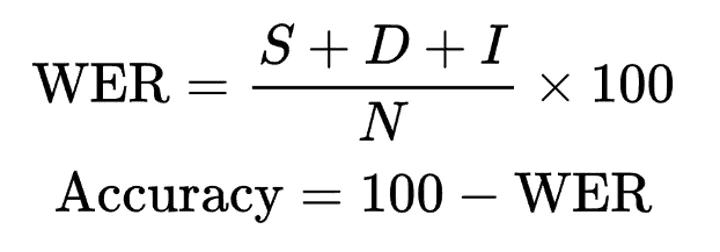
To illustrate how you align a reference and recognized transcript, here’s an example:

Each sentence in the transcript is evaluated for accuracy, and the resulting WER reflects the effectiveness of the ASR model or speech recognition APIs.
Here, the ASR system omits information about seeing the dog. There are two clear ways to align this, but they both lead to different WERs.
Firstly, in alignment 1 you align “and I saw a cat” with the end of the reference. This leads to 5 deletions “and I saw a dog” which is a WER of 50%.
Alignment 2 leads to an extra error due to the substitution of “dog” with “cat”. This leads to a WER of 60%. By minimizing the edit distance, you’ll ensure you get the alignment with the minimal WER (in this case Alignment 1).
The process of recognizing speech and converting spoken language into text can introduce errors, which are quantified by the resulting WER.
As mentioned above, the main pitfall is incorrectly giving importance to some errors over others. Higher WER can result from real life datasets with noisy data, diverse accents, and additional factors that impact WER but do not necessarily reflect the true capabilities of speech recognition systems or ASR systems.
Minor problems such as misspellings of names or the wrong number of repeated words – say when someone speaks with a stutter – are penalized just as heavily as errors that cause misinformation.
In addition, it is very difficult to get a test set that has no mistakes from human transcribers. Human transcriptionists are often better at capturing technical language, acronyms, and context, which automated ASR systems may struggle with.
This introduces an intrinsic floor which means it is impossible for the system to reach 0% WER. On top of mistakes, they often write the transcript using a different specification. After all, there are many ways to write the same thing. Here are two examples:
Numeric entities: can be in written or spoken form and there are differences in formatting such as commas in large numbers. Also, there are different ways of saying currency such as 10 pounds, 10 quid and a tenner. All are the same and will be £10 in written form.
Dates: there are countless ways of writing which include different ordering or shortened forms.
Other factors, such as domain-specific language and speaker variability, can also affect WER.
If the reference is misaligned with the ASR output this can lead to increasing WER significantly. It can be trivial to normalize some of these issues, but the problem is harder when comparing across vendors because they all have different ways of formatting. WER is not necessarily reflecting the actual usability of the transcript, as it can be influenced by external factors.
Furthermore, in order to get an accurate alignment, you must strip all punctuation and convert characters to lower case. Punctuation and capitals at the start of sentences or for proper nouns are essential for readability, but WER doesn’t take any of that extra information into account. ASR systems may perform differently on real world datasets, such as those with noisy data or varying accents, compared to controlled benchmarks.
Let’s see a particularly bad example of how WER can be completely misaligned with reality. It is important to identify which errors are most impactful for the intended use case, rather than relying solely on WER.